
Обновлено: 07.11.2024
Оптимизация сайта начинается с семантического ядра. Как показывает практика, большинство приходящих на продвижение владельцев интернет-магазинов, корпоративных порталов и владельцы сайтов услуг имеют об этом самое отдаленное представление. В этой статье разберем основные положения: что такое семантическое ядро, зачем оно нужно, как с ним работать.

Что такое семантическое ядро
Семантическое ядро – это список сгруппированных ключевых слов и фраз, которые наиболее точно описывают тематику и основное содержание сайта или отдельной страницы сайта. В зависимости от тематики, характера магазина, сегмента рынка и объёма сайта семантическое ядро может состоять как из десятка запросов, так и из сотен тысяч.
Все запросы разбиваются на группы, называемые «семантическими кластерами» – некоторые запросы должны размещаться на одной общей странице. Несовместимые запросы, относящиеся к разным кластерам, на одной странице продвигаться не могут.
Семантические кластеры – это основа структуры сайта, подчиненная определенной логике. Один кластер – одна страница. Чем более продумана логика, тем больше шансов, что структура сайта не станет препятствием для продвижения. К 2019 году одной из самых популярных техник создания структуры сайта стала техника «силосования»(SILO), обеспечивающая простую и четкую структуру сайта. SILO (“бункер”) относится, скорее, к терминам из сферы архитектуры сайта, и может вообще не подразумевать работы с семантикой, поскольку основывается на принципиально другой логике.
Семантическое ядро, используемое в работе, чаще всего представлено либо в виде “карты релевантности”, таблицы, где объединенные в группы ключевые слова сопровождаются URL целевых страниц, либо в виде mind-maps, отображающей ключевые слова в древовидной форме.
Грамотно составленное семантическое ядро позволяет выстроить эффективную SEO-стратегию, максимизировать охват целевой аудитории и улучшить позиции сайта в поиске. Оно лежит в основе оптимизации контента и всей работы над сайтом в целом.
Зачем нужно собирать семантическое ядро
Основное применение семантического ядра – это выстраивание правильной структуры сайта в целом, его разделов и отдельных посадочных страниц. Благодаря этому можно понять, какие запросы наиболее перспективны для продвижения, что именно ищет ваша целевая аудитория, а что в принципе не стоит затрачиваемых ресурсов. Запросы, относящиеся к разным кластерам, не могут эффективно продвигаться на одной или нецелевой странице.
Однако и это далеко не все сферы применения семантического ядра. Вот лишь несколько дополнительных задач, которые можно решить углубленной проработкой поисковой семантики.
- Масштабирование сайта за счёт неохваченных ранее групп запросов и теговых расширений;
- Оптимизация страниц, уже попавших в топ-10, но не дотягивающих до топ-3;
- Подготовка контентных планов, основанных на интересах аудитории и бизнес-задачах;
- Выявление скрытых интентов посетителей благодаря анализу поисковых запросов;
- Использование поисковой семантики для проведения рекламных кампаний.
Как собирают семантические ядра
Поисковые системы развиваются, меняется и инструментарий оптимизатора. Когда-то было достаточно составить некоторую базовую структуру целевых ключевых слов, вытянуть данные по этим ключевикам из систем статистики и сторонних сервисов, разбить на группы (кластеры) и внедрить на сайт.
Вот основные шаги для сбора семантического ядра сайта:
- Составьте список ключевых слов и фраз, которые описывают тематику и основное содержание вашего сайта. Это должны быть слова, по которым пользователи будут искать информацию на вашем сайте.
- Проанализируйте конкурентные сайты – посмотрите, какие слова и фразы используют они. Это поможет дополнить ваш список релевантными ключевыми запросами.
- Воспользуйтесь инструментами ключевых слов – Wordstat, Google Keyword Planner, “Букварикс” и др. Это поможет узнать популярность запросов и дополнить список.
- Разделите слова на основные, второстепенные и дополнительные – так вы сможете сфокусироваться на самых важных.
- Проанализируйте полученный список с точки зрения пользовательского интента (намерения) – какую цель/потребность выражает пользовательский запрос. Группируйте по схожим интентам.
- Составьте карту релевантности: схему или таблицу, представляющую собой общую структуру сайта на базе групп запросов и страниц, к которым привязана каждая группа.
- Отслеживайте динамику и при необходимости обновляйте ядро новыми актуальными запросами.
Рассмотрим процесс более подробно.
Подготовка базовой структуры и парсинг
На первом этапе нужно составить базовую структуру семантического ядра. Для этого нужно хотя бы минимальное погружение в тематику, чтобы не совершить ошибок. Критически важно, чтобы на этом этапе структуру проверил эксперт в тематике.
Большое подспорье в этот момент – изучение доменов конкурентов, уже получивших высокую видимость в тематике. На базе таких сайтов создаётся сводная таблица, основанная на меню и структуре разделов сайтов. Хорошая идея – подготовка карты слов или тематической карты, наглядно структурирующей основные ключевые слова и темы сайта.

Тематическая карта слов
Из базовых запросов (их называют “маркеры”) нужно получить общую подробную базу ключевых фраз. После сбора можно приступать к первичной чистке. Для сбора используются либо парсеры (например, Key Collector), либо готовые базы поисковой семантики (keys.so, “Букварикс”, Wordkeeper и т.п.). Кроме того, используется парсинг похожих запросов, поисковых подсказок и т.п. Благодаря этому получаем максимально полную базу как в глубину, так и в ширину – то есть список запросов с вспомогательными словами и различными синонимами.
После сбора можно приступать к чистке: удалять откровенно “мусорные” запросы, не относящиеся к тематике, с нулевой частотностью.
Кластеризация
Второй этап – кластеризация: разбивка запросов по группам-кластерам, определяющим линейную структуру сайта. Запросы одного кластера должны продвигаться по одной посадочной странице (хотя бывают исключения, когда нужно разбить кластер на две или даже более “посадок”). Важно сопоставить реальные группы запросов с возможностями и потребностями бизнеса, поэтому этот этап всегда проводится с привлечением заказчика.
После согласования основных групп проводится скоринг запросов, или приоритизация, то есть оценка предварительной оценки ключевых слов с точки зрения эффективности и важности для продвижения и получения заданного эффекта.
Результатом этой фазы становится создание новых посадочных страниц и целых разделов, оптимизация меню или создание его для нового сайта, а также выявление релевантных страниц. Их может быть более одной для уже работающего сайта, и это может быть причиной недостаточно высокого ранжирования.
Выявление контента, необходимого для ранжирования
После подготовки базовой структуры с группами ключевых фраз начинается одна из самых сложных частей подготовки семантики: выявление ключевых слов и поисковых сущностей, напрямую связанных с основными запросами. Современные алгоритмы поисковых систем оценивают не единственный документ в рамках сайта, и не единственный пласт семантики в рамках документа. Оценивается семантический граф, и если какой-то узел этого графа не имеет вспомогательных узлов – он может быть признан в принципе нерелевантным запросу.
Инструментарий на этом этапе используется достаточно сложный. В самом просто случае оптимизатор просто создаёт сводную табличку, основанную на структуре посадочных страниц сайтов из топа. Отмечается наличие видео, таблиц с ценами, вспомогательных блоков (отзывы, сертификаты и т.п.), каких-то медиа-материалов.
Однако этот способ нельзя назвать самым эффективным, хотя он и позволяет выявить некоторые закономерности. Для более эффективной работы используется углубленный анализ данных с применением графового анализа, NLP (обработкой естественного языка), инсайтов, основанных на бизнес-аналитике и т.п.
Нужно понимать, что наличие или отсутствие какого-то термина или поисковой сущности в рамках страницы может самым драматическим образом повлиять не только на ранжирование по запросу, но и на релевантность. Классический пример: отсутствие сертификата на собственную продукцию на странице производителя привело к выпадению из топа поисковой выдачи с 1 на 10-11 позиции, и потерю 2/3 всего трафика из Google.
Как выглядит готовое семантическое ядро
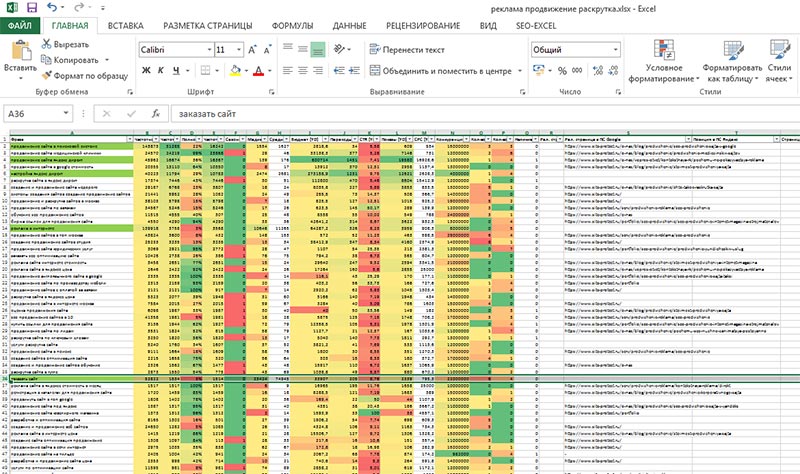
Примерно так может выглядеть таблица с семантическим ядром на стадии скоринга и приоритизации запросов.
Единого формата оформления не существует, но есть общие требования. Если вы заказываете специалисту подготовку семантики для сайта, или делаете это самостоятельно, убедитесь, что собранные вами ключи оформлены правильно.
- Все ключи должны быть поделены на группы (кластеры). Просто список ключевых слов для сайта – бесполезен, работать с ним нельзя.
- Каждый ключевик в семантическом ядре должен сопровождаться заданными характеристиками, определяющими его важность и качество. Процесс определения важнейших ключевиков в ядре называется скорингом запросов, или приоритизацией ключевых слов. Их мы рассмотрим отдельно. Пока вам достаточно определить важнейшие для ваших задач характеристики ключей. Обычно это частотность, сезонность, показатель коммерческости, конкурентность, показатель кликабельности на выдаче (CTR) и некоторые другие.
Скоринг ключевых слов с высокой степенью точности выявляет нулевые, “накрученные” и бесперспективные запросы ещё на стадии подготовки семантического ядра.
Типовые ошибки в работе с семантикой
Характер поисковых запросов меняется со временем. Когда-то частотные и конверсионные запросы могут терять своё значение, характер, заменяться другими, более перспективными и востребованными. Именно поэтому работа с коррекцией и масштабированием семантического ядра не должна прекращаться никогда.
- Без распределения запросов по кластерам с использованием статистики реальной поисковой выдачи в коммерческом сегменте невозможно получить работающую структуру: одна посадочная страница – один кластер поисковых запросов.
- Важно определить не только маркерный запрос (основной для кластера), но и его синонимы. В противном случае вы упустите значительное количество ключей, которые могут и должны продвигаться на этой же посадочной странице. Для выявления таких ключей стоит использовать либо анализ страниц конкурентов в топе, либо воспользоваться возможностями сторонних сервисов (например, keys.so, который покажет родственные ключевые слова со степенью похожести на маркерный запрос).
- Запросы одного семантического кластера нельзя раскидывать на разные посадочные страницы. Это приведет к каннибализации запросов, в результате чего поисковик едва ли поймёт, какую конкретно страницу ранжировать по заданному ключу. В таких случаях алгоритм на всякий случай понижает в выдаче обе.
- Включение в семантическое ядро запросов-пустышек. Страницы, сделанные под нулевые запросы – поисковый мусор, ухудшающий общее качество сайта и отрицательно влияющие на продвижение на уровне хоста (всего сайта).
- Неверная оценка качества запросов на базе частотности Яндекс-Вордстат: накрутки поведенческих факторов в Яндекс приводят к тому, что реальная частотность накручиваемых ключевиков неизвестна, а рост частотности со временем связан не с популярностью запроса, а с деятельностью спам-ботов.
- Коммерческие и информационные запросы на одну страницу распределять ни в коем случае нельзя. Единственное исключение – спектральная выдача, в которой сочетаются как коммерческие, так и информационные запросы.
- И, пожалуй, самая важная ошибка, которую можно считать фатальной: нерелевантность выбранных запросов на уровне бизнеса. Приступая к выбору ключевых слов, вы должны понимать: если у вас монобренд, или малый ассортимент – вы не сможете конкурировать с мегамаркетами и агрегаторам по общим частотным запросам. Ваши 10 товарных позиций не могут сравниться с тысячами, нужно сегментировать предложение, опираясь на собственное уникальное торговое предложения. Не «мебель купить», а «купить мебель лофт Италия», например. Да, трафика будет меньше – но меньше будет и конкуренция, а посетители будут вашими потенциальными покупателями, а не людьми, ищущими дешёвейшие табуретки из жёваного картона.
Пример актуализации семантики
Небольшой агрегатор образовательных курсов. Спустя полгода после начала индексации сайта трафик из поиска практически отсутствовал несмотря на качество контента и технические характеристики сайта.
Анализ показал, что структура сайта не соответствует актуальному семантическому графу, и основные категории не имеют необходимых вспомогательных узлов.
После подготовки рекомендаций владелец сайта существенно масштабировал структуру разделов, добавив необходимые для ранжирования подкатегории. В результате этого удалось практически сразу значительно увеличить трафик из поиска, фактически не добавляя ничего, кроме новых теговых страниц.

Собираем первичную семантику с помощью сервисов Яндекс
Подготовка первичного семантического ядра с помощью сервисов Яндекс включает в себя несколько обязательных стадий.
- Подготовка базовой структуры семантического ядра, основанная на типовых структурах сайтов из топа поисковой выдачи
- Получение общего списка семантических запросов из Яндекс Вордстат на базе составленной ранее структуры
- Фильтрация и чистка полученного списка ключевых слов
- Собираем частотность по Яндекс-Директ
- Очищаем список от нулевых и мусорных запросов
- Кластеризуем список ключей по топу
Поскольку статья предназначена не для начинающих SEO-специалистов, а для владельцев сайтов, я не буду подробно расписывать каждый шаг. Вы должны всего лишь в общих чертах понимать логику процессов, чтобы знать, что такое поисковая оптимизация, а нюансы вам при необходимости раскроет ваш оптимизатор. Имейте в виду, что реализация описываемых операций может здорово отличаться: у каждого специалиста – свои инструменты, свои навыки, свои представления и опыт. Здесь я рассказываю, как выполняю такую работу сам.
Общий первичный список запросов из Яндекс-Вордстат
На этой стадии мы просто задаём базовые (маркерные) запросы общего характера, по которым хотели бы получить ключи. Частотность на этой стадии нас не интересует, берем только базовую частоту. Важны другие моменты:
- Запросы должны соответствовать тому региону, на который мы продвигаемся
- Характер запросов должен соответствовать характеру сайта (либо коммерческие, либо только информационные)
Для сбора семантики удобнее всего использовать какой-нибудь парсер. Чаще всего это KeyCollector, программа для работы с семантикой по умолчанию для большинства российских оптимизаторов. Достаточно загрузить базовый список маркерных запросов, и парсер соберет всё, что есть в Wordstat на них похожего.
Выгружаем список полученных запросов в формате Excel, нас ждёт процесс первичной фильтрации от мусора и нерелевантных ключей.
Удаляем нерелевантные ключи
Из полученного списка ключей нам предстоит убрать следующие:
- Не относящиеся к заданной геолокации. Там обязательно попадутся запросы, имеющие прямое отношение к другим городам и даже странам. «Купить в Тольятти», «шифоньер дешево Воронеж» и всё такое.
- Запросы витального характера, имеющие отношения к другим магазинам и веб-ресурсам. Обычное дело: люди хотят купить в «Леруа Мерлен», Hoff или «Авито». Нам такие запросы неинтересны.
- «Своими руками». Да, зачастую в чисто коммерческие запросы случайно попадают запросы от людей, которые ничего покупать не собираются. Сносим.
- «Скачать бесплатно». Такого добра тоже хватает. Сюда, собственно, можно сразу добавить запросы с ключами «дешево», «по акции», «промо-код» и всё такое, если ваше торговое предложение явно недешевое, а скидок у вас не предвидится.
- «Б/у». Если вы не торгуете секонд-хендом, это тоже нужно удалять.
- Дополнительно стоит снести запросы с ключами «фото», «видео» и им подобные – возможно, они пригодятся нам в дальнейшем, во время масштабирования семантического ядра. Пока же запросы от «холодной» аудитории, только приценивающейся к товару или услуге стоит удалить.

С помощью расширений для Excel многие рутинные операции с семантическим ядром можно проводить гораздо быстрее
Ну, а после удаления откровенно нерелевантных и мусорных запросов надо пройтись и посмотреть, не остались ли в списке ключи, явно не имеющие к вам отношения.
Таким образом, наш список сокращается в несколько раз, и мы получаем первую итерацию поисковых запросов. Однако теперь время проредить их по частотности.
Собираем частотность по Яндекс-Вордстат
Важно понимать, что нельзя просто так обратиться к сервисам Яндекс и получить данные, с которыми можно сразу работать. Большинство новичков не понимает, что обычный запрос без операторов даст очень искаженные цифры. Это потому, что сервисы Яндекс предполагают несколько типов:
- запросы с широким соответствием, включающие все слова из заданных вами
- запросы с фразовым соответствием, включающие только эти слова и словоформы в любом порядке
- условно точное соответствие со словами именно в этой словоформе, но без фиксации порядка слов
- точное соответствие, когда место словоформ в запросе закреплено.
И не забудьте, что собирать запросы нужно за достаточно большой промежуток времени (например, год), и с заданной региональностью. Запросы, собранные за месяц, могут показать неточную частотность, если речь – о сезонном товаре или услуге, и ориентироваться на такие цифры нельзя.

Нам понадобится максимум информации по статистике использования ключей, поэтому начинаем парсить частотность из Яндекс-Директ. А по окончанию нас ждут удивительные открытия.
Пример из алко-тематики. Запрос «купить коньяк годе» заданный с широким соответствием покажет нам просто бешеную частотность. Может показаться, что вся страна в едином порыве желает покупать коньяк дома Годе чуть не ежедневно. Точное соответствие показывает, что вспоминают о нём пару-тройку раз в год, это запрос-пустышка, а его частотность накручена словами «купить» и «коньяк».
Экспортируем список запросов с частотностью и начинаем анализировать
Фильтруем запросы по частотности
Итак, у нас получается минимум три столбца с общим, фразовым и условно точным соответствием пользовательским ключевикам. Однозначно сносить стоит «нулевки» уровня фразового соответствия. Они в принципе не принесут вам трафика, с такими запросами никто к поиску не обращается.
Затем надо пристально посмотреть на микрочастотные запросы. Это условная величина, и для каждого сегмента рынка она своя. Как минимум, удалить стоит те запросы, с которыми обращаются к поиску менее 10 раз в год. А можно и те, которые используют чуть чаще, но всё равно мало. Вам решать, под какие запросы вам точно нужны посадочные страницы – это ваши бюджеты и бизнес-задачи.
На этой же стадии стоит оценить запросы с точки зрения коммерческой составляющей. Делать вручную это неудобно, неточно и долго, лучше воспользуйтесь одним из веб-сервисов. Здравый смысл также никто не отменял.
В результате получаем список запросов, которые точно должны быть представлены на вашем сайте. Время объединить их в кластеры.
Кластеризация
Существует три способа кластеризовать ядро:
- Вручную
- Автоматически
- Полуавтоматически
«Ручной» способ – самый неточный, поскольку субъективен. В этом случае человек использует свою логику, а она, как правило, очень отличается не только от машинной, но и характерной для других людей.
Автоматический способ использует данные, полученные из поисковой выдачи. Этот способ намного более точен, хотя и он может допускать ошибки по вполне объективным причинам. Я использовал парсер KeyAssort, но с выходом KeyCollector 4 всю работу можно выполнять в нём.
Результаты автоматической кластеризации стоит проверить вручную. Это и есть третий, полуавтоматический способ, который я и рекомендую использовать.
Для автоматической кластеризации по топам вам понадобится инструмент. Кластеризаторов много, большинство из них – платные, точность и удобство тоже отличается. Выберите свой, удобный для вас.
Следующий шаг – выбор алгоритма кластеризации. Их три:
- «жесткий» (hard)
- «мягкий» (soft)
- «умеренный»
Для кластеризации коммерческих запросов традиционно рекомендуется использовать жесткий алгоритм с порогом 3 как наиболее точный и практичный. Чем выше порог – тем меньше точность. Мягкая кластеризация применима к информационным запросам, поскольку позволяет на одной странице продвигать большее количество запросов без ущерба для продвижения – такова особенность информационных запросов, границы их размыты.
После того, как вы загрузили список запросов в сервис кластеризации, он немного подумает (это может занимать часы), и вы получите список групп-кластеров, объединяющих запросы постранично. Оцените полученное. Возможно, что-то стоит удалить, а что-то – объединить.
Что делать после составления семантического ядра?
Итак, вы составили семантическое ядро для своего сайта, и теперь у вас есть таблица, в которой ключевые слова сгруппированы и распределены по посадочным целевым страницам. Можно приступать к следующим этапам:
- Оптимизируйте целевые посадочные страницы в соответствии с семантикой.
- С помощью текстовых анализаторов проверьте релевантность: действительно ли целевые страницы соответствуют заданным ключевым словам?
- Если оптимизированные страницы ещё не проиндексированы поисковыми системами – настройте сканирование и индексирование.
- Проверьте, соответствуют ли целевые страницы сайта релевантным с точки зрения поисковой системы. Бывает так, что поисковые алгоритмы считают релевантной страницей нецелевую. В этом случае нужно понять причины и определить дальнейшие действия по устранению этой проблемы.
- Загрузите своё семантическое ядро в сервис мониторинга ранжирования, чтобы понимать, как оцениваются посадочные страницы по заданным ключевым словам и какова динамика ранжирования.
- Регулярно проверяйте, не изменился ли характер поисковых запросов, и не появились ли новые. Используйте их для масштабирования своего семантического ядра.
Изменения в работе с семантикой на 2024 год
Ориентировочно с 2021-2022 года стало очевидно, что традиционные поисковые алгоритмы, оценивающие контент традиционными алгоритмами, основанными на ключевых словах, утратили значительную часть своего “веса” в общей формуле. В первую очередь это коснулось наиболее частотных ключей – тех запросов, по которым поисковые системы накопили значительные объёмы данных. Если до этого преобладал синтаксический поиск, основанный на использовании ключевых слов, то к 2024 он почти вытеснен контекстным поиском, учитывающим смысл запроса и намерения пользователей, уже использовавших эти ключевые слова ранее.
Вместе с этим изменился и подход к структурированию сайта. Если раньше для ранжирования по запросу посадочная страница должна была содержать какие-то уточняющие ключи, уникальные для этой страницы в рамках сайта, то теперь с большей степенью вероятности поисковая система выбирает для ранжирования категорию верхнего уровня, не содержащую этих ключевых слов. Иными словами: если вы обращаетесь к поиску с запросом “купить красное ватное одеяло недорого”, поиск выберет общую категорию “одеяла”, а не подкатегорию “красные ватные одеяла”.
Это происходит потому, что большие веса приобрели не текстовые метрики, а пользовательские поведенческие сигналы. Поисковая система знает, что пользователи с похожими запросами и интересами решали свою проблему с общим URL из индекса, и отбрасывают второстепенную информацию по дальнейшим действиям этих пользователей на сайте. Причиной такого поведения поисковых систем можно считать не только усложнение алгоритмов ранжирования, но и банальную экономию ресурсов. Совершенно незачем держать в индексе тысячи страниц разной степени релевантности, если основной спрос может закрыть по сути дела десяток-другой сайтов.
Значит ли это, что уже не нужно создавать посадочные страницы под низкочастотные и микрочастотные запросы, если они всё реже попадают в поисковую выдачу? – Разумеется, нет. Просто в большей мере трафик на такие страницы будет попадать не из поисковой выдачи, а в результате переходов пользователя по сайту. Они по-прежнему необходимы для презентации ассортимента. Однако нужно понимать, что спрос на представленные товары, услуги или информацию с этих страниц должен быть реальным, иначе они не смогут получать трафик и попадут в категорию низкокачественных и непопулярных страниц.
Используем LLM для кластеризации
Фактически, только сейчас появился полноценный инструментарий, с помощью которого можно действительно работать со смыслом, полноценной семантикой, а не синтаксисом, где оцениваются только ключевые слова и статистика их использования. Речь о Больших Языковых Моделях, среди которых – ChatGPT, LLama, Claude и т.п.
Поисковые системы активно внедряют семантические алгоритмы, работающие со смыслом текста, а не ключевыми словами. А значит, оптимизатор может и должен учитывать это в своей работе. Для этого проще всего использовать эмбеддинги (векторные вложения) – числовое представление слов, пассажей и целого текста. Самый простой способ – извлечение эмбеддингов поисковых запросов в уже подготовленном кластере и сопоставление их между собой (например, по косинусному сходству). В качестве отправной точки можно взять либо самый частотный общий запрос кластера (маркер), либо общую формулировку интента, тут можно поэкспериментировать. Те запросы, что в явном виде выпадают из кластера, скорее всего относятся к нему по ошибке.
Пример:

Как видно из скриншота, некоторые запросы в явном виде выпадают из соответствия главному. Возможно, их стоит выделить в отдельную группу запросов.
Всё, что вам нужно для работы – это доступ к одной из LLM по API (можно выбрать одну из моделей, специально разработанных для извлечения векторных вложений, например, ada-2 от Open AI), соответствующий скрипт Python и таблица в Excel или Google Docs.
Ещё один способ оценить структурно-семантические проблемы по сайту – сопоставить существующее семантическое ядро с векторными вложениями отдельных страниц. Делается это по той же схеме: вам понадобятся эмбеддинги поисковых запросов и выгрузка эмбеддингов контента страниц сайта. Таким способом можно найти страницы, идентичные по смыслу и борющиеся за выдачу, или обнаружить слишком низкое соответствие запросам.
Полностью кластеризовать семантическое ядро в ChatGPT, Claude или Gemini я бы не советовал, но это отличный способ обнаружить возможные ошибки в кластеризации по топу поисковой выдачи или с помощью логического распределения запросов по группам.
Заключение
В результате сбора поисковых запросов, фильтрации, кластеризации и фильтрации их у вас получился рабочий список поисковых ключей, структурированный, отображающий частотность. Хорошо бы ещё оценить сезонность запросов и конкуренцию, но это уже другая история, мы здесь это рассматривать не будем. У вас есть готовый материал для проектирования структуры сайта, добавления, объединения и даже удаления разделов и страниц, подготовки текстового контента и метатегов. Именно с создания семантического ядра и начинается сайтостроение и поисковое продвижение.
В дальнейшем, по итогам индексации, ранжирования и анализа статистики трафика, необходимо будет регулярно проводить ревизию семантического ядра, ориентировочно – хотя бы раз в год. Таким образом можно найти новые точки роста, незадействованные возможности, исправить ошибки. Актуализацию семантики рассмотрим в одной из следующих статей.


Здравствуйте, Виктор! Спасибо Вам за полезную статью! Материал изложен понятно и доступно, четко и по делу.
Виктор, позвольте попросить у Вас совет.
Планирую создать нишевой блог по теме «Тайм-менеджмент для научных работников».
Какие поисковые запросы мне следует выбрать для семантического ядра: запросы, связанные с тайм-менеджментом, или же запросы, связанные с научными работниками и научной деятельностью? Или возможен какой-то третий вариант?
Казалось бы, логичен первый вариант (запросы по тайм-менеджменту), но… Боюсь, что в этом случае на блог станут заходить многие из тех, кто не имеет никакого отношения к научной работе. Уровень отказов будет расти, поведенческие показатели – падать…
Виктор, посоветуйте, пожалуйста, как грамотно собрать СЯ, чтобы избежать этих проблем?
Заранее благодарен Вам за ответ!
Здравствуйте, Игорь. Вопрос не самый простой: с инфо-ресурсами сейчас вообще трудно, и тема специфическая. Но я бы отталкивался от первого варианта: основной вес – на ключ “тайм-менеджмент” без акцента на уточнении для кого, если нет особой специфики. Если цель – трафик, то не совсем та аудитория вреда не причинит.

А отталкиваться я стал бы на старте от запросов “Люди также спрашивают” (PAA): это могут быть как части одной статьи, так и темы для отдельных статей. Чем полнее вы охватите тему – тем выгоднее для поисковых систем вести трафик именно к вам.
И особое внимание я уделил бы синдикации контента – с помощью больших посещаемых площадок, где точно есть ваша аудитория. Контентная сеть в любом случае сильнее одного лишь сайта.
Виктор, спасибо Вам большое за оперативный и развернутый ответ! Постараюсь спокойно и взвешенно его осмыслить и, если потребуется что-то уточнить, еще разок Вас побеспокою. Вы не против?
Да, не вопрос. Но лучше пишите в ТГ, это оперативнее. Система комментариев WP – не самая удобная и оперативная площадка.
Спасибо, Виктор!