
Обновлено: 09.03.2024
Пагинация – традиционный способ разбивки контента на многостраничный список с присвоением каждой странице условного номера. Таким образом традиционно структурируют листинги (списки) товаров, статей, ленты сообщений. Пользователь видит сортировку по заданному по умолчанию критерию (дата публикации, цена, популярность и т.п.) и вывод карточек товаров или ссылок на статьи в заданном количестве. Но как настроить пагинацию на пользу SEO?

Что такое пагинация
Пагинация – это метод структурирования объёмных листингов с помощью разбиения списков на отдельные динамические страницы. Используется на страницах категорий, если список представленных на них товаров, услуг или ссылок на информационные страницы достаточно большой.
Структурирование за счёт разбивки больших листингов на отдельные страницы используется и на коммерческих сайтах, и на новостных, и в блогах. Традиционные форумы с большими топиками также используют пагинацию для управления страницами.
Пагинация – не единственный способ организации и представления контента. Она используется преимущественно для минимально структурированного контента, и в ряде случаев может быть заменена слайдерами, подборками, динамической подгрузкой контента и т.п.
Сам по себе листинг (список товаров, услуг или информационных материалов) уже нельзя считать полноценной структурой посадочной страницы: это только один из её структурных элементов. Поэтому если страница представляет собой только часть этого листинга, польза её для посетителя едва ли высока. Если посетитель вынужден просматривать страницы листинга, значит, вы просто не предусмотрели никаких вспомогательных средств для поиска и презентации интересующей людей информации.
Традиционная схема настройки пагинации
Изначально пагинация настраивалась с помощью тегов rel=prev и rel=next с указанием предыдущих и следующих URL в серии. Каждая страница ссылалась на себя как на каноническую. С помощью этих тегов Google мог объединять все страницы пагинации в одну серию, организовывать структуру и понимать, что речь не о страницах-дублях.
В 2019 году представители Google объявили, что теги rel=prev и rel=next больше не поддерживаются и признаны устаревшими. Так как же поступать с пагинацией в нынешних условиях? Каковы лучшие практики для многостраничного контента?
Давайте рассмотрим основные проблемы, связанные с разбиением категорий постранично и индексированием такого контента.
Основные проблемы, связанные с пагинацией
- Страницы пагинации чаще всего не несут никакой пользы для посетителя. Это всего лишь способ презентации контента какой-то категории. Едва ли кто-то будет прокликивать все эти страницы в поисках товара или статьи в блоге, чтобы найти нужное. Для этого есть более удобные способы: фильтрация, сортировки, коллекции, теги.
- Страницы пагинации могут ранжироваться по одним и тем же ключевым словам. А это значит, что при некоторых условиях они могут перебивать ранжирование у основной (целевой) страницы. Собственно, в некоторых случаях это может быть даже показательно: поисковой системе не нравится “сеошная портянка” на целевой странице – огромный бестолковый текст, напичканный ключевыми словами, и алгоритм начинает ранжировать случайную страницу пагинации. Это хороший сигнал, что текст на целевой странице нужно убирать или корректировать.
- Незакрытые от индексации страницы пагинации отнимают лимиты сканирования. И Google, и Яндекс начинают всё больше экономить свои ресурсы, затрачиваемые на сканирование интернета и оценку обнаруженных URL. Вебмастер должен прилагать все усилия, чтобы выделяемые для его сайта ресурсы поисковые системы не тратили понапрасну. Новые товарные карточки могут и должны попадать в индекс через карту сайта в формате XML – sitemap.xml, либо другими доступными способами (через обход сайта по счётчику метрики, API, внутреннюю перелинковку карточек и категорий). Пагинация для этого не нужна. Однако товарные карточки, имеющие входящие ссылки только из карты сайта, не могут быть найдены людьми и не передают никакого веса страницам верхнего уровня.
Типовые практики для работы с многостраничными категориями
Важные условия
Выбирая способ организации многостраничного контента в рамках SEO, надо учитывать несколько условий.
- Основным типом устройств, с которых посетители заходят на сайты, становятся смартфоны. Уже сейчас смартфоны – это около 80% всего интернет-трафика. Пагинация на смартфонах – далеко не самый удобный способ организации многостраничных листингов. Даже сам Google с 2022 года начал использовать “бесконечную” подгрузку контента в поисковой выдаче на смартфонах.
- Даже сам Яндекс, использующий на поисковой выдаче пагинацию, на 3-5 странице начинает показывать капчу. Логично: нормальный человек едва ли станет перебирать страницы листинга, а вот поведенческий бот – вполне вероятно.
- Помимо добавления ссылок на страницы листинга, есть и другие способы организовать контент. Пример – подгрузка нового контента средствами AJAX, “бесконечная прокрутка”. URL не меняется, просто по запросу пользователя подгружаются новые пункты листинга.
- Google и Яндекс сканируют и индексируют сайты по-разному, и по-разному реагируют на настройки сканирования. Например, Яндекс до сих пор плохо работает с каноническим адресами и метатегами “robots”. Вернее, он их учитывает, но не сразу, и может и вовсе проигнорировать на какое-то время. А это – скачки позиций и проблемы с ранжированием целевых страниц.
А теперь рассмотрим основные способы настройки страниц пагинации в рамках SEO. Начнём со старых стандартов, уже устаревших.
Устаревшие методы настройки пагинации для SEO
Сохранение схемы rel=prev и rel=next + canonical
Это старая привычная схема организации разбивки контента по страницам. Подразумевается, что страницы пагинации открыты для сканирования в robots.txt. добавляется тег canonical, указывающий на основную страницу категории, метатег “robots” не запрещает индексировать страницы пагинации.
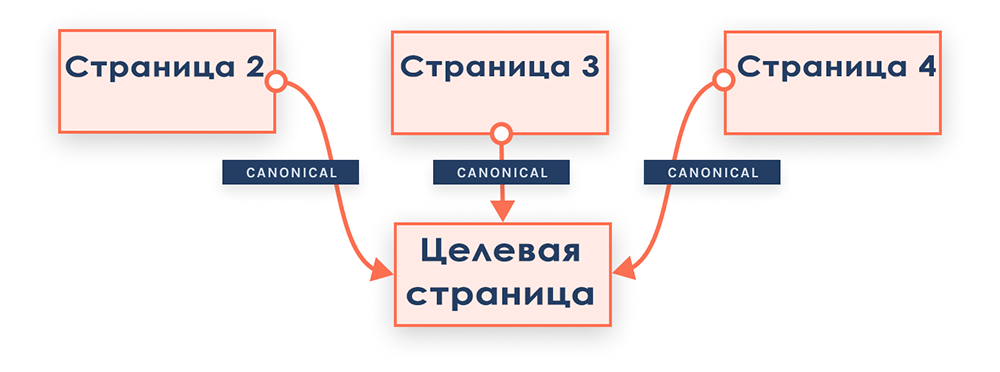
Страницы пагинации ссылаются на главную (целевую) страницу как на каноническую.
Если основная (каноническая) страница категории по каким-то причинам не нравится поисковикам, высок риск, что ранжироваться будут случайные страницы. Типичный пример: на целевой странице есть небольшой и ненужный текст, на страницах пагинации его нет. Этого достаточно, чтобы ПС сочли каноническую страницу спамной. Кроме того, этот способ подходит не для коммерческих категорий, а для сайтов информационного типа, структурировать которые средствами тегирования намного сложнее.
Простую схему с использованием канонического адреса предлагают и представители Яндекса:
Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, то советую настраивать атрибут rel=”canonical” тега на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.
Однако надо учитывать, что для Яндекса одного лишь канонического URL может оказаться недостаточно, и без прямого запрета на сканирование и индексацию по продвигаемым ключам может начать ранжироваться нецелевая страница.
Вывод страницы с полным листингом и присвоение canonical ему
Старая схема, разработанная под Google и плохо подходящая для Яндекса. Подразумевается, что вы выводите полный список URL категории на одну общую страницу, а страницам пагинации назначается канонический URL, ведущий на эту общую страницу.
Способ подходит для категорий достаточно небольшого объёма, поскольку действительно большой листинг скажется на производительности, особенно если это не просто список с ссылками, а полноценные карточки с изображениями-превью и т.п.
Большой минус – это продвижение таких страниц в Яндексе. Кроме того, ценность такого листинга как продающей страницы невысока, поскольку не предоставляет пользователю никаких преимуществ: это просто огромный ворох товаров, услуг или ссылок на статьи. Но самый большой недостаток – это проблемы текстового характера. Вы можете сильно переспамить, а возможностей проработать семантику «в ширину» не получить.
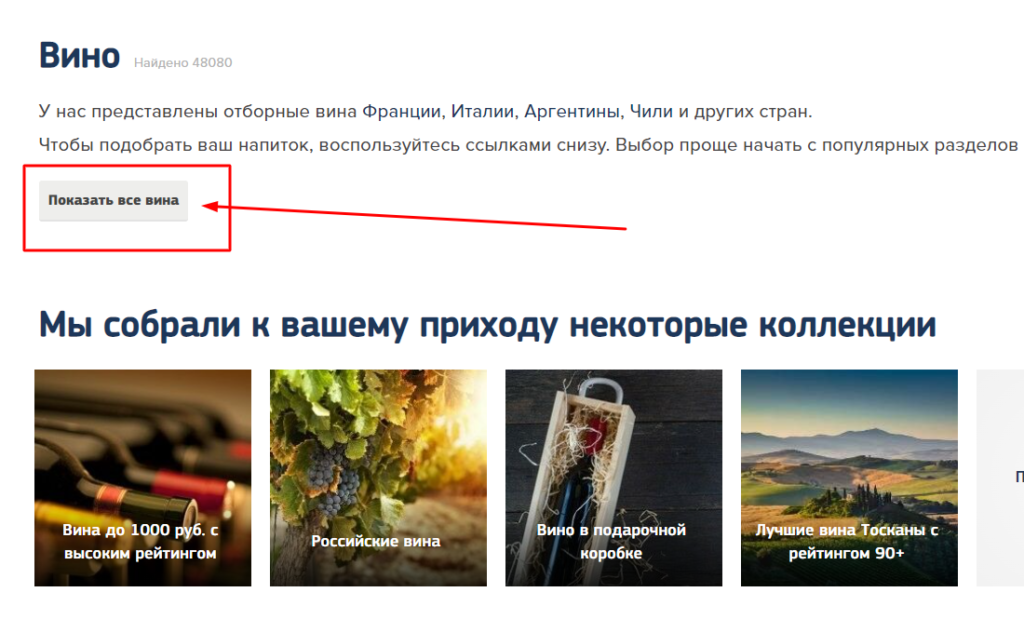
Пример похожей реализации на сайте Winestyle: ссылка на листинг со страницы-хаба. Нюанс: листинг закрыт для индексации тегом robots
Реализация листинга на AJAX с подгрузкой контента
Это одна из современных схем работы с большими листингами. Пользователь просто прокручивает страницу или нажимает на кнопку «Загрузить ещё» – и листинг дополняется.
Однако есть некоторые проблемы технического характера. AJAX до сих пор плохо обрабатывается в Google и никак – в Яндексе, так что при реализации «в лоб» такая техника равнозначна полному закрытию пагинации от сканирования на уровне robots.txt.
Оптимальный вариант – добавлять ссылки на подгружаемые страницы пагинации, объединяя таким образом подгрузку средствами AJAX с HTML-ссылками на новые URL. Таким образом пользователь получит лучшие впечатления от взаимодействия с сайтом, а поисковые роботы смогут получить доступ к страницам пагинации. Кроме того, не будет потери ссылочных весов в рамках алгоритма PageRank: передаваемый внутренними страницами ссылочный вес не потеряется.
Запрет на индексацию с помощью метатега robots со значением “noindex, follow” + canonical
В этом случае страницы пагинации запрещают вносить в индекс с помощью метатега robots со значениями “noindex, follow”: это значит, что страницы не рекомендовано вносить в индекс, но по ссылки на них поисковый робот должен учитывать.
Главный минус этого способа – поисковые системы часто пренебрегают этим метатегом, поскольку он носит чисто рекомендательный характер. Кроме того, поисковые роботы будут тратить лимиты на сканирование сайта на обход страниц, которые изначально подаются как мусорные и не предназначенные для внесения в поисковый индекс. Справка Google отмечает, что речь не о запрете на индексирование, но о запрете на отображение в поиске.
Учитывайте, что вес со страниц, закрытых для индексирования, учтен не будет. Об этом говорил небезызвестный Джон Мюллер, и это логично: для поискового робота нет никакого смысла ходить по ссылкам на деиндексированных страницах.
Кардинальный запрет на сканирование пагинации в robots.txt
Запрет страниц пагинации на уровне robots.txt. – устаревший способ работы с многостраничными листингами, способный привести к проблемам со сканированием сайта и появлению страниц-“сироток”, имеющих ссылки только из sitemap.xml.
Чаще всего страницы пагинации имеют околонулевую ценность для пользователя. Семантически они дублируют контент основной страницы и могут перебивать релевантность. Это очень плохой UX, когда посетитель вынужден листать товары вместо того, чтобы получать готовое коммерческое предложение.
В отличие от предыдущего варианта с запретом на индексацию, но без запрета на сканирование, этот способ позволяет лучше сэкономить лимиты на обход сайта поисковыми роботами: чтобы понять, что страница не должна попасть в индекс, робот в любом случае должен её сначала скачать. И в любом случае, тег вообще ничего не гарантирует, это всего лишь рекомендация с вашей стороны.
Естественно, использовать этот способ стоит только при соблюдении ряда условий:
- Ваша основная посадочная страница должна быть не листингом, а хабом, максимально полно отображающим ассортимент и упрощающим процесс выбора для посетителя.
- Вы должны убедиться, что все товарные карточки в рамках каталога хорошо перелинкованы и получают достаточное количество внутренних ссылок (с помощью подкатегорий, тегов, блоков “похожие товары” и “Товары этого производителя” в рамках шаблона товарной карточки и т.п). И разумеется, карта сайта в формате sitemap.xml должна регулярно обновляться, чтобы поисковые роботы вовремя находили новый контент и могли его проиндексировать.
Актуальные практики реализации пагинации
- Используете ли вы вариант с бесконечной прокруткой или привычные ссылки на страницы пагинации, убедитесь, что у вас есть доступные для роботов ссылки вида <a href> на каждой странице. Убедитесь, что на любой странице пагинации есть ссылка на первую, целевую страницу.
- Используйте для страниц пагинации правильные URL. Они должны быть уникальными, и содержать параметр типа ?page=n или нечто подобное. Такие параметры позволяют поисковым системам распознавать пагинацию и консолидировать (объединять) их с основной целевой страницей.
- Не используйте тег canonical с указанием главной страницы как канонической для страниц пагинации. Они не дублируют друг друга. Канонизированные страницы не индексируются, и фактически выпадут из веб-графа.
- Не дублируйте контент первой страницы листинга на страницах пагинации. Если там есть текст – пусть он будет только на первой странице. Страницы пагинации должны быть предельно уникальны.
- Избавьтесь от идентификаторов фрагментов (#) в URL. Google официально игнорирует их.
- Теги rel=next и rel=prev уже не поддерживаются. Не надо их специально удалять, если они уже есть. Вместо них используйте микроразметку.
- Используйте теги preload, reconnect или prefetch, чтобы ускорить переход между страницами для пользователей.
- Существует два типа визуальной пагинации: “Следующая/Предыдущая” и нумерация страниц по цифрам. Выберите тот, который лучше всего подходит для вашего объема контента.
Микроразметка для пагинации
Качество настройки пагинации может повлиять на то, как поисковые системы будут индексировать ваши страницы и содержащийся на них контент – ссылки, статьи, продукты и многое другое.
Пример:
Категория называется “100 блюд из картофеля” и имеет URL-адрес и изображение, связанные с ней. Она включает в себя две страницы, “Страница 1” и “Страница 2”, каждая из которых имеет свой URL и название.
<div itemscope itemtype=“http://schema.org/Series”> <span itemprop=“name”>100 блюд из картофеля</span> <link itemprop=“url” href=“https://example.ru/100-blyud-iz-kartofelya”> <link itemprop=“image” href=“https://example.ru/100-blyud-iz-kartofelya-thumbnail.jpg”> <! - Page 1 → <div itemprop=“hasPart” itemscope itemtype=“http://schema.org/WebPage”> <a itemprop=“url” href=“https://example.ru/100-blyud-iz-kartofelya/page/1”> <span itemprop=“name”>100 блюд из картофеля - Стр 1</span> </a> <meta itemprop=“position” content=“1”> </div> <! - Page 2 → <div itemprop=“hasPart” itemscope itemtype=“http://schema.org/WebPage”> <a itemprop=“url” href=“https://example.ru/100-blyud-iz-kartofelya/page/2”> <span itemprop=“name”>100 блюд из картофеля - Стр 2</span> </a> <meta itemprop=“position” content=“2”> </div> </div>
Как решить проблему с индексацией бесконечной прокрутки
Поисковые роботы не прокручивают страницу и не кликают по кнопкам. Они переходят по ссылкам. Если поисковый робот не может увидеть дополнительный контент, доступный только после действий пользователя – это проблема. Решается она одним способом: вы должны обеспечить прямой доступ к этому контенту.
Пагинация, основанная на прокрутке (бесконечный скролл), не позволит поисковому роботу нормально сканировать сайт. Робот не умеет прокручивать, не умеет нажимать на кнопки. Ему нужны ссылки, чтобы по ним переходить. Если их нет – контент на страницах пагинации не будет обнаружен обычными средствами.
Googlebot видит страницу не так, как человек. Известно, что он может отображать 9-10 тысяч пикселей, либо примерно 2,8 высоты дисплея. Если дополнительный контент попадает в эту зону просмотра, он может быть просканирован.
- Создайте отдельные страницы компонентов, которые будут использованы в бесконечной прокрутке. Простая проверка – это отключение JS: в этом случае посетитель должен получить ссылки на страницы пагинации, вне зависимости от файлов-куки.
- Страница с бесконечной прокруткой имеет единый URL вне зависимости от объёма подгруженного контента. Ваша задача – для каждого подгружаемого компонента сделать уникальный URL, который может использовать поисковый робот или человек.
- Каждый блок подгружаемого контента в бесконечной прокрутке должен содержать уникальный в рамках сайта контент. Точно так же, как на страницах пагинации. Это подразумевает так же и уникальные метатеги для каждого блока, и иметь каноническую ссылку на саму себя.
Вот фрагмент JavaScript, чтобы дать вам представление о работе бесконечной прокрутки:
window.onscroll = function() {
// Проверяем, прокрутил ли пользователь страницу до самого низа
if (window.innerHeight + window.scrollY >= document.body.offsetHeight)
{
// Вы находитесь в нижней части страницы, загрузите больше контента здесь.
// Можно сделать AJAX-запрос, чтобы получить дополнительный контент.
// После загрузки нового контента его нужно добавить к существующему контенту на странице.
// Не забудьте реализовать обработку ошибок и индикаторы загрузки, если это необходимо.
}
};
В этом коде:
- window.onscroll – это слушатель событий, который запускает функцию, когда пользователь прокручивает страницу.
- window.innerHeight представляет собой высоту области просмотра браузера.
- window.scrollY показывает, насколько страница была прокручена по вертикали.
- document.body.offsetHeight дает общую высоту документа.
- Если сумма window.innerHeight и window.scrollY равна или превышает document.body.offsetHeight, это означает, что пользователь прокрутил страницу до нижней части страницы, и вы можете запустить загрузку дополнительного содержимого.
Кроме того, не забудьте о разделении контента на управляемые секции, то есть собственно страницы пагинации. Это обеспечит доступность даже при отключенном JavaScript и сохранит целостность URL.
При реализации бесконечной прокрутки очень важно разделить контент на небольшие, доступные секции. Это гарантирует, что пользователи с отключенным JavaScript смогут беспрепятственно получать доступ к контенту и перемещаться по нему. Избегайте дублирования этих разделов.
Примеры:
- Пример 1: site.com/knigi&page=1
Эта структура URL указывает на первую страницу контента в категории “Книги”. - Пример 2: site.com/knigi?lastid=123
Использование такого уникального идентификатора, как “lastid”, помогает поддерживать уникальность URL, позволяя пользователям получать прямой доступ к определенным разделам. - Пример: site.com/knigi#1
Хотя использование идентификатора фрагмента URL (#) не лучший вариант для SEO, оно все же обеспечивает некоторую доступность. Однако лучше использовать параметры запроса или чистые URL, когда это возможно.
Улучшение пользовательского опыта с помощью replaceState и pushState
Рассмотрите возможность использования replaceState и pushState для дальнейшего улучшения пользовательского опыта в зависимости от поведения пользователей на вашем сайте.
- replaceState: когда действия пользователя, такие как щелчок или прокрутка, похожи на щелчки мыши. Он заменяет текущий URL в истории браузера без создания новой записи.
- pushState: чтобы пользователи могли легко вернуться к ранее прокрученному контенту. Он добавляет новую запись в историю браузера.
Вот пример:
// Использование pushState
history.pushState({ page: 'scroll' }, 'Scrolled Content', '/knigi/detskie?page=2');
// Использование replaceState
history.replaceState({ page: 'scroll' }, 'Scrolled Content', 'knigi/detskie?page=3');
Используя эти методы стратегически, вы сможете обеспечить более плавный и удобный для пользователя опыт при реализации бесконечной прокрутки.
При оптимизации бесконечной прокрутки учитывайте доступность, структуру URL и улучшение пользовательского опыта за счет манипулирования состояниями. Такой подход гарантирует, что все пользователи, включая тех, у кого отключен JavaScript, смогут эффективно перемещаться по вашему контенту, улучшая при этом SEO и вовлеченность пользователей.
Общие ошибки пагинации, которых следует избегать
- Использование тега “noindex” вместо канонических тегов может помешать поисковым системам правильно индексировать ваши страницы.
- Статические URL-адреса для пагинации – это не выход. Лучше использовать динамические параметры в URL.
- Убедитесь, что страницы, не относящиеся к текущей категории, возвращают ошибку 404.
Заключение
Основная проблема неправильной пагинации – ограничение доступа к контенту. Ошибки в настройках приводят к тому, что ссылки со страниц пагинации попросту не учитываются поисковыми роботами.
Чтобы избежать этого подводного камня, запомните эти золотые правила:
- Используйте для пагинации удобные ссылки <a href>, к которым могут получить доступ краулеры.
- Убедитесь, что оптимизирована только первая страница в последовательности, и удалите любой SEO-специфический контент из URL пагинации.
- Помните, что боты Google не могут прокручивать страницу или нажимать на нее, поэтому убедитесь, что весь ваш контент доступным даже без JavaScript.
- Дважды проверьте доступность URL-адресов страниц в консолях поисковых систем
Перед тем, как принимать решение и делать настройки структуры листингов, соберите важнейшую информацию по общей структуре сайта, распределению ссылок по страницам, оцените возможности сканирования сайта поисковыми роботами – и протестируйте принятую гипотезу.


Виктор, спасибо за статью!
Подскажи, на каких сайтах можно увидеть реализацию пагинации AJAX + HTML?
Мария, спасибо за оценку.
AJAX + HTML в основном используется в новостниках, вот для примера из сегодняшней ленты новостей: https://iz.ru/1354888/2022-06-24/zakharova-nazvala-lozhiu-zaiavleniia-glavy-mid-germanii-o-golode
По мере прокрутки подгружается новый контент со своим статичным URL. В коммерции я такое не встречал, но там обычно и смысла подгружать то, что юзверь не просил, и нету.
Добрый день. Спасибо за статью.
При всех вышеописанных методах в Яндексе страницы пагинации попадают в Малополезные. Это нормально?
Да, есть такая проблема. По сути, это никак не связано с текстовыми метриками, уникальностью и т.п. Яндекс оценивает трафик, и ниже определенного порога всё закидывает в МПК. Знаю проект в очень узкой b2b-тематике с крайне низким поисковым спросом, где главная страница сайта, стоящая в топ-3, периодически вылетает в статусе МПК. Нет трафика – и Яндекс переклинивает.
В этом случае нужно либо наращивать целевой трафик, если там спрос вообще есть, либо мудрить с настройками индексирования. Если МПК по хосту слишком много – это проблема для хоста.