LSI (Latent Semantic Indexing) – это метод анализа и индексирования текста, используемый для определения семантической связи между словами и понятиями в текстовых документах. Алгоритм LSI позволяет определить тематическую связь между словами, даже если они не синонимы или явно не связаны друг с другом.
При использовании метода LSI текстовые документы представляются в виде математических моделей, известных как матрицы терминов-понятий. В этих матрицах каждый столбец представляет термин, а каждая строка представляет документ. Затем проводится снижение размерности матрицы с помощью сингулярного разложения (Singular Value Decomposition – SVD), это позволяет найти скрытые связи между терминами и документами.
Модель LSI сама по себе никогда не использовалась в поисковых алгоритмах: этот метод анализа был разработан до эпохи интернета, и использовался для концептуального поиска документов в библиотечных коллекциях. В практике SEO термином LSI совершенно ошибочно называют любые методы с дистрибутивной семантикой и выявлением близости слов: любой контент, соответствующий интенту пользователя, а не заданным для поиска ключевым словам.
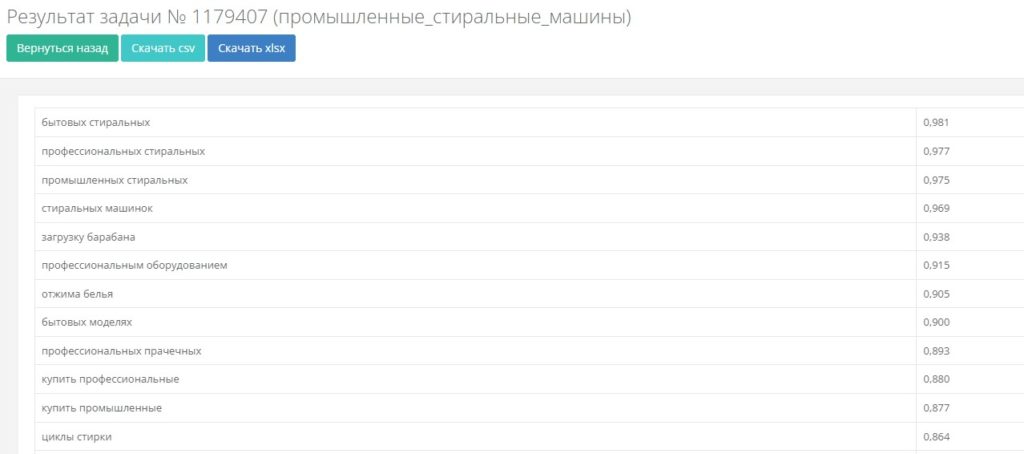
Пример выгрузки тематически связанных слов по запросу “промышленные стиральные машины” из сервиса “Акварель-Генератор”. В правой колонке – коэффициент соответствия основному запросу.
Основные принципы LSI
- Текст представляется в виде «мешка слов». Порядок слов и их близость друг к другу значения не имеют.
- Документ относится к той или иной тематике/группе на основании терминов (слов), которые в нем содержатся и частоты этих терминов (количества раз, которые они встречаются в документе).
- Каждое слово имеет единственное значение. Это не совсем корректное допущение, но оно необходимо для построения модели.
Сфера применения
- LSI помогает в определении связи между словами, идентификации семантических аспектов документа и анализе его смысла.
- Релевантные результаты поиска. LSI применяется в поисковых системах для улучшения результатов поиска. Он позволяет вывести более релевантные документы, даже если они не содержат точно совпадающие ключевые слова.
- Кластеризация документов. LSI позволяет группировать схожие документы в кластеры на основе их семантической связи. Это помогает организовать большие объемы информации и облегчает навигацию по текстовым корпусам.
Латентно-семантическое индексирование (или латентно-семантический анализ) применялось к многочисленным задачам из области компьютерных наук – от моделирования памяти до компьютерного зрения.
Хофман (Нofmann, 1999) предложил первоначальное вероятностное расширение основных методов латентно-семантического индексирования (pLSI – probabilistic LSI).
Более формальной основой вероятностной модели латентной переменной для снижения размерности является латентное размещение Дирихле (Latent Dirichlet Allocation – LDA). Эта порождающая модель приписывает вероятности документам, не принадлежащим обучающему множеству. Она была расширена для иерархической кластеризации. Вай и Крофт (Wei and Croft, 2006) провели первое крупномасштабное исследование модели LDA и продемонстрировали, что она значительно превосходит (языковую) модель правдоподобия запроса), но уступает модели релевантности, хотя в модели релевантности, в отличие от модели LDA, предусмотрена предварительная обработка запроса. Те и др. (Teh et al., 2006) обобщили этот подход, предложив иерархические процессы Дирихле (Hierarchical Dirichlet рrосеssеs) вероятностную модель, позволяющую извлекать группу (в нашем случае – документ) из бесконечной смеси латентных тем, при этом одной теме может соответствовать много документов.
