
Обновлено: 25.08.2024
Тег “Canonical” – это указание поисковой системе, какую страницу из нескольких идентичных по контенту следует считать основной. С его помощью вы можете помочь выбрать поисковым роботам целевой URL для внесения в индекс, чтобы избежать дублирования контента и ранжирования нецелевой страницы (например, технического дубля).
Содержание
скрыть
Для чего используется Canonical
Задача тега “Canonical” – настройки индексации. Он не запрещает сканировать, он расставляет приоритеты среди страниц, чей контент схож до полной идентичности.
- Типовая ситуация: у вас на сайте может быть множество полных или частичных дублей, чей контент практически одинаков, и все они хорошо подходят под какой-то запрос, отличаясь лишь параметрами адреса (URL). Типовой пример – это страницы пагинации, сортировки или страницы фильтров. В этом случае поисковые алгоритмы могут определить целевую страницу неправильно.
- Проблемы с настройками CMS, когда одна товарная карточка выводится в разных категориях, и её URL меняется в зависимости от категории вывода. При ошибочном проектировании товарного каталога такое можно встретить часто. Указание эталонного адреса избавит сайт от появления дублей в индексе, если невозможно внести кардинальные изменения в структуру каталога.
С помощью тега Canonical вы можете указать нужный URL. Именно он будет внесен в поисковый индекс, и вы сможете избежать вероятных проблем с ранжированием, постоянной переклейкой запросов с одной страницы на другую и т.п. - Особый случай – добавление канонического адреса файлам, например, PDF. Этот вопрос мы рассмотрим ниже.
Canonical для пагинации: да или нет?
С помощью Caninical можно склеить страницы, объединяя характеристики, не относящиеся к текстовым: графовые, ссылочные, поведенческие и т.п. Иными словами, все метрики неканонических страниц будут подклеены к канонической странице.
В интернете можно найти рекомендации не назначать канонический адрес первой (основной) странице пагинации, вместо этого либо добавляя каждой странице ссылку на себя или общую ссылку на страницу, выводящую все ссылки на контент раздела (будь то товарные карточки, статьи и т.п.).
С моей точки зрения это ошибочный подход, и вот какова логика.
- Под каждый кластер запросов на сайте должна быть только одна целевая страница. Её копии или страницы-каннибалы должны быть деиндексированы и закрыты от индексирования.
- Ассортимент магазина определяется не количеством товарных карточек, а товарной матрицей на базе категорий этих товаров. Сама же страница категорий должна содержать достаточное количество ожидаемых поисковой системой ключей в заданных текстовых зонах, чтобы соответствовать требованиям к текстовым характеристикам. Если сайты в топе выводят минимум 40 товарных карточек – отталкивайтесь от этой цифры.
- Яндекс умеет консолидировать (склеивать) страницы пагинации, используя Canonical. Это означает, что страницы останутся в индексе, передавая свои метрики основной посадочной странице. Google рекомендует не использовать такую схему, поскольку канонизированные страницы он обходить не станет и с большой степенью вероятности деиндексирует их. Однако он в любом случае не станет их ранжировать по каким-то запросам, как и регулярно сканировать: ему для этого нужны дополнительные сигналы, пользовательские или ссылочные, так что ущерба от такой схемы быть не должно.
Страницы пагинации не несут никакой дополнительной пользы для посетителя: если потенциальный клиент не может найти нужное сразу же, зайдя на посадочную страницу, или с помощью фильтрации, вспомогательных категорий, сортировок – нет смысла отправлять его перелистывать странички. Страницы пагинации не должны ранжироваться по запросу, и у категории должна быть единственная основная посадочная страница, способная полноценно представить ваше коммерческое предложение.
Особенности обработки в разных ПС
Разные поисковые системы по-разному обрабатывают канонические адреса по причине отличий в алгоритмах. Например, Яндекс сначала индексирует страницу, а потом выбрасывает её из индекса, обнаружив ссылку на каноническую страницу. Google же с большой степенью вероятности сразу же не станет вносить неканонический URL в индекс, поскольку метрики страницы просчитывает сразу, в реальном времени.
В любом случае вы должны понимать: канонические адреса – это не директивы для роботов, это сигналы, которые они могут учесть – а могут и проигнорировать, если обнаружат противоречия, или получат более важные сигналы (ссылки, поведение пользователей и т.п.). Если канонический адрес не указан, то Google может выбрать его самостоятельно. Для этого он использует:
- Общую релевантность страницы
- Внутренние ссылки
- Наличие ссылки на страницу в sitemap.xml: по умолчанию все адреса из карты сайта считаются каноническими
Кроме того, Google поддерживает междоменные canonical: если один и тот же контент будет найден на разных хостах, Google может выбрать основной самостоятельно. Это одна из причин, почему никогда не стоит копировать чужой контент: вы можете даже не узнать, что Google склеил вашу страницу с канонической на другом хосте.
Когда необходимо указывать канонический адрес страницы
Канонические адреса рекомендуется использовать во всех случаях, когда один и тот же контент можно найти на отличающихся URL сайта.
Тег Canonical можно рассматривать как вариант постоянного перенаправления поискового робота в рамках сайта (301 редирект), действующий без принуждения. Поисковая система может учесть этот тег, а может и проигнорировать.
Кроме того, канонический адрес поможет вам избежать появления в рамках сайта дублей, искусственно формируемых злоумышленниками-конкурентами с помощью get-параметров.
Почему появление дублей – это плохо
Сами по себе нечеткие и полные дубли – не нарушение, однако вы можете столкнуться с рядом серьёзных проблем.
- Если контент доступен по разным URL, вы можете получить ссылки с внешних ресурсов на неправильный адрес. Без указания канонической ссылки «вес» этих ссылок не будет передан на целевую страницу.
- Роботы ходят по ссылкам, и количество переходов за один сеанс может быть жестко лимитировано. Если поисковый алгоритм сочтёт, что дублей на сайте слишком много, он понизит приоритет сканирования сайта как некачественного.
Типовые ошибки настроек канонических адресов
Указание канонического адреса — это очень мощное средство управления индексацией сайта. Ошибки в их использовании могут стать причиной появления множества проблем.
Перечислим самые распространенные ошибки:
- URL, указанный в качестве канонического, отвечает кодом, отличающимся от 200 (будь то «Не найдено», «Перемещено навсегда» и т.п.).
- Страница, указанная как каноническая, содержит метатеги Robots со значением “Noindex”, либо закрыта для сканирования в файле robots.txt.
- Канонический URL отсутствует в карте сайта sitemap.xml, зато присутствует неканонический.
- В качестве канонического адреса указан относительный адрес, а не абсолютный.
- В качестве канонической указана страница, не связанная со ссылающейся страницей по контенту – например, товарная карточка ссылается как на каноническую на главную страницу сайта.
- Страницы ссылаются друг на друга перекрестно, что приводит к ошибочным перенаправлениям поискового робота по кольцу, или каноническая страница содержит указание на другую страницу.
Может ли страница ссылаться сама на себя
Теоретически, если на вашей странице в качестве канонической ссылки указан URL этой же страницы, вы получаете кольцевую ссылку. Практически же кольцевая ссылка отличается от канонического адреса целями – это не приглашение роботу перейти по ссылке.
Основные требования
- Канонический URL должен отдавать код 200
- Он не может быть запрещён для сканирования в файле robots.txt
- Он должен присутствовать в карте сайта sitemap.xml
- Canonical не должен содержать метатега robots со значением “Noindex”
- Страница, указанная как каноническая, может ссылаться на себя, но не может в качестве канонической указывать другую страницу
Важно понимать: использование Canonical должно устранять из индекса технические дубли. Канонические страницы не должны использоваться для похожих страниц, или страниц, оптимизированных под похожие запросы.
Преимущества использования
- Благодаря настройкам канонических адресов вы можете передать ссылочный вес заданной целевой странице. Даже если страницы-дубли получают ссылки извне, этот вес будет передан канонической странице. Точно так же это работает и в рамках внутренней перелинковки.
Примечание. Это не работает в Яндекс, поскольку Яндекс в настоящий момент использует алгоритмы на базе Browse Rank, и никакие «веса» по таким ссылкам не передаёт. - Если вами используется синдикация контента, поисковой системе будет сложно понять, какой именно сайт считать первоисточником. Настройка Canonical на внешних ресурсах упростит задачу. Однако чаще всего такая возможность недоступна, и надо сделать так, чтобы контент на основном ресурсе успел проиндексироваться и приобрел статус канонического.
- Указание канонических адресов упрощает сканирование сайта, перенаправляя поискового робота на действительно важные узлы сайта. Таким образом вы можете не только расставить акценты, но и сэкономите лимиты обхода, что важно как для Google, так и для Яндекс.
Как добавить Canonical
Есть несколько основных способов.
- В современных CMS, как правило, процесс автоматизирован. Ваша задача – выбрать страницу и просто указать канонический адрес в предусмотренном в рамках системы управления сайтом поле.
- Ещё один способ – использовать HTTP-заголовок. Таким образом можно добавлять канонические адреса в документы, отличающиеся от HTML, например, в PDF-файлы. Сделать это можно с использованием файла .htaccess. Как это сделать – смотрите пример ниже.
Этот тег всегда добавляется в раздел <head>. Для большинства популярных CMS есть возможность сделать это либо штатными средствами, либо с помощью дополнительных SEO-модулей или плагинов.
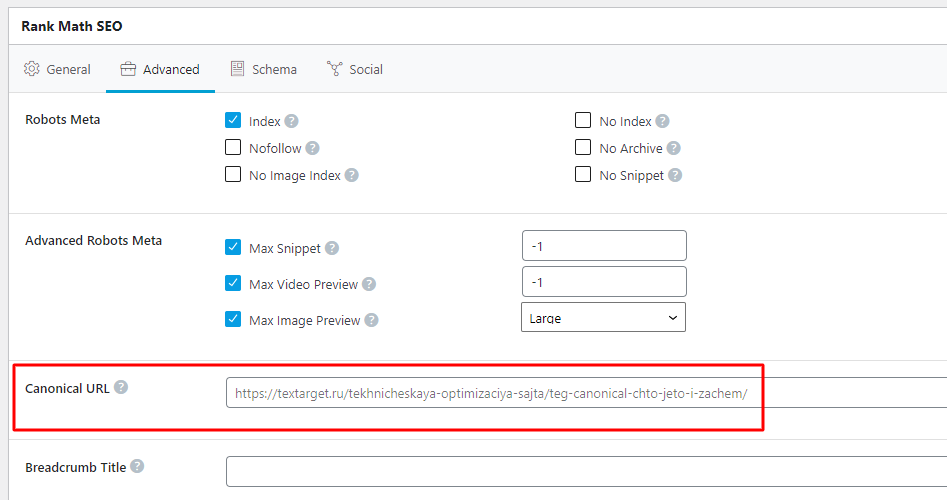
Скриншот SEO-настроек плагина Rank Math: как видите, средствами WP канонический адрес настроить очень просто. По умолчанию подставляется собственный адрес, но ничто не мешает вставить нужный URL
Однако есть случаи, когда сделать это стандартными средствами нельзя:
- Используемая система управления сайтом может иметь ограничения;
- Документ на заданном URL может быть не в формате HTML и попросту не иметь области <head> (например, это касается PDF-файлов, изображений, текстовых документов и т.п.
В таком случае есть смысл добавлять Canonical с помощью заголовков HTTP.
Зачем PDF-файлу Canonical
Самый распространенный случай: у вас есть один и тот же документ на сайте в двух форматах, обычный HTML и PDF. Так часто делают с различными руководствами, буклетами и т.п. PDF во многом удобнее странички на сайте: их проще скачивать, распечатывать, пересылать. Благодаря этому PDF может получать больше внешних ссылок и пользовательских сигналов, из-за чего поисковая система будет считать PDF более важным документов в рамках сайта, чем копия в HTML.
И всё бы ничего, если бы не следующие моменты:
- Вы не можете отслеживать активность пользователя в рамках PDF;
- В PDF нельзя интегрировать код системы ретаргетинга;
- Для того, чтобы ознакомиться с документом в формате PDF, пользователю уже необязательно заходить к вам на сайт, он может получить этот файл от других пользователей – и эти данные выпадут из статистики.
Часто бывает и так, что интернет-магазины или сайты дистрибьюторов выкладывают у себя PDF с официального сайта. Это неуникальный контент, дублирующий десятки других таких же файлов на других сайтах. И уже были ситуации, когда тот же Google признавал такие файлы принадлежностью какого-то внешнего ресурса. Не лучше ли попытаться взять этот вопрос под контроль?
Некоторые вебмастера закрывают PDF от сканирования и индексации средствами robots.txt, однако этот вариант едва ли можно считать оптимальным, во всяком случае – единственным. Подробно о настройках robots.txt и способах его использования.
Как внедрить канонический адрес через заголовок HTTP
Разумеется, вам понадобится доступ к файлу настроек сервера .htaccess. Чтобы добавить тег к файлу “example.pdf” добавьте в htaccess следующее:
<Files "example.pdf">
Header add Link "< http://site.ru/docs/ >; rel=\"canonical\""
</Files>
В заголовке HTTP вашего PDF должно вывестись следующее:
Link: < https://site.ru/docs/ >; rel=”canonical”
Если вы используете единую структуру имен всех файлов, которым хотите присвоить канонический адрес, можно задать шаблон по типу
RewriteRule ([^/]+)\.pdf$ - [E=FILENAME:$1]
<FilesMatch "\.pdf$">
Header add Link "< https://site.ru/docs/%{FILENAME}e.html >; rel=\"canonical\""
</FilesMatch>
И к этому несколько замечаний:
- При указании имени файла не добавляйте каталог, просто укажите фактическое имя файла. Учтите, что слаг URL-адреса может не соответствовать реальному пути к файлу.
- Между открывающим < и закрывающим > и URL канонической ссылки есть пробел.
- Помните, что .htaccess – очень важный файл, и ошибки могут привести к неработоспособности сайта и серверным ошибкам 5**. Тестируйте не на рабочем сервере.
Предлагаемый код – всего лишь шаблон, который может не сработать на вашем сервере.
Когда Canonical не нужен
Часто в руководствах можно встретить такой пример: «Если сайт доступен по разным адресам, надо настроить каноническую ссылку на главное зеркало». Так делать не надо. Всё, что должно решаться 301-ми редиректами (постоянным направлением на серверном уровне) – должно решаться именно так.
Другой пример – когда «канонизировать» пытаются мобильную версию. Вот у нас сайт на мобильном субдомене, вот ссылка на основную версию на десктопе (или наоборот). Так тоже делать не надо: если вы хотите показать роботу, что у сайт есть версия для другого типа устройств, используйте метатег rel=”alternate” со ссылкой на эту версию.
И разумеется, не стоит добавлять каноническую ссылку на многоязычный контент, когда у вас на сайте есть несколько версий одного и того же контента, но на разных языках, и предназначенного для разных стран. Для указания роботам альтернативных языковых версий контента используйте атрибут “hreflang”. Смысл – указать альтернативную версию, а не основную, рассматриваемую как единственная и правильная.

