
Обновлено: 19.10.2024
Анализ логов сервера – важный инструмент поисковой оптимизации. Серверные журналы access_log содержат самую точную информацию о том, как поисковые системы сканируют ваш сайт. Помогите поисковым роботам выполнять их работу, и ваши усилия по продвижению намного упростятся.
Если в техническом состоянии сервера и сайта есть проблемы, то другие усилия по продвижению сайта будут напрасны. Техническая оптимизация – ключ к тому, чтобы поисковые системы могли сканировать, индексировать и анализировать сайт. Все вопросы в этом отношении должны быть закрыты до того, как вы начнете заниматься поисковым маркетингом.

Содержание
скрыть
Что такое логи
Что такое лог-файл? – Это текстовый файл, содержащий список любых действий, которые происходят на сервере, в операционной системе, сетевом устройстве или программе. Нас интересует access_log, своего рода журнал посещений, содержащий список всех запросов, сделанных к серверу.
Помимо access_log есть и другие логи, например, перечень серверных ошибок (error_log), но в рамках поисковой оптимизации нам надо оценить, кто, откуда и с какой периодичностью обращается к серверу.
Как это работает
Когда пользователь вводит URL в браузер (или кликает по ссылке), браузер разделяет URL на три компонента:
Доменное имя преобразуется в IP через сервер доменных имен (DNS), и устанавливается соединение через один из портов, где находится запрошенный файл.
Затем http-запрос методом GET отправляется на веб-сервер через заданный протокол, браузер получает соответствующий html-код, и вы видите на своем мониторе запрошенную страницу.
Каждый запрос записывается в лог как «хит».
Каждый раз, когда пользователи или боты посещают сайт, в лог-файл вносится множество записей, ведь единственная страничка в интернете может подразумевать десятки запросов к хосту. Логи можно использовать для технического аудита и обработки ошибок. Проанализировав лог, вы можете понять, какие ресурсы сканируют боты, как часто и с какой периодичностью, обнаружить аномалии и найти проблемы, которые никаким другим способом обнаружить нельзя.
Из чего состоит лог-файл
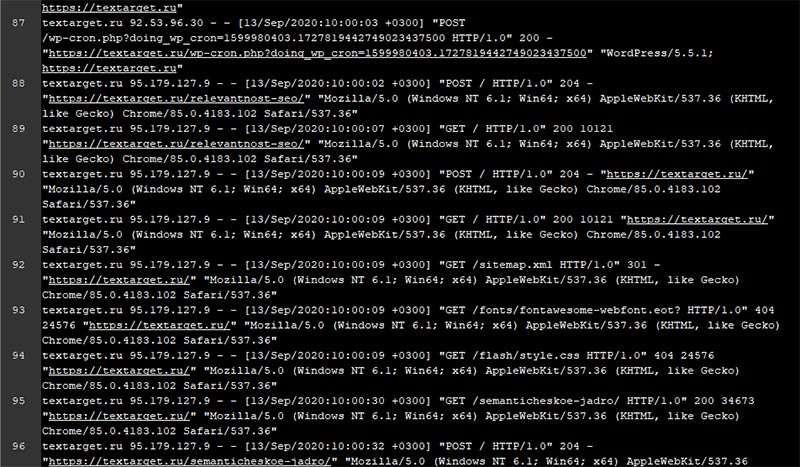
Примерно так выглядит лог-файл, открытый в текстовом редакторе. Согласитесь, работать с ним в таком виде можно, но очень уж сложно, и стоит использовать соответствующее программное обеспечение.
Структура лога определяется типом сервера и многими настройками, но в любом логе можно найти следующее:
- IP клиента (посетителя)
- Отметку о времени визита
- Метод передачи данных (GET/POST)
- Запрошенный URL
- Код состояния HTTP
- Использовавшийся User-Agent (браузер)
В некоторых случаях в журнале фиксируются загруженные байты, время, необходимое для загрузки ресурса на сервере для клиента, и т.п.
Как получить доступ к логам
Как уже было сказано, всё определяется вашим сервером и его настройками. Место хранения логов зависит от конфигурации сервера. Часто они сохраняются в корневой папке вашего сайта, если журналирование вообще включено. Вот адреса логов по умолчанию в зависимости от серверной операционной системы:
- Debian, Ubuntu
/var/log/apache2/access.log - CentOS, Red Hat, Fedora
/var/log/httpd/access_log - FreeBSD
/var/log/httpd-access.log
Чаще всего используются три типа веб-серверов: Apache, NGINX, IIS. Если запись логов включена, вы можете зайти в заданную папку вашего сайта и просто скачать нужный журнал, используя FTP-клиент или файловый менеджер панели управления хостингом. Некоторые хостеры позволяют заказать лог за заданный период, вы просто получите ссылку на архив.

Некоторые хостеры позволяют заказать логи за заданный период
Сложнее, если вы используете CDN. В этом случае вам нужно обратиться к провайдеру CDN и получить логи с ближайшей конечной точки между сервером, обслуживающим ваши ресурсы, и клиентом. В случае использования CDN логи с вашего веб-сервера ничего не дадут, поскольку к нему обращаются только в случае очистки кэша. И запрашивать логи нужно со всех серверов, входящих в CDN.
Основные проблемы с получением логов
- Сервер может быть совсем старым или нетипичным, и вам придётся читать техническую документацию чтобы узнать, как включить запись логов, а потом ждать, когда соберется достаточный объём информации.
- Хуже, если вы, SEO-специалист, не имеете полноценного доступа к серверу, а клиент не понимает, зачем всё это, или не доверяет вам. В таком случае осваивайте искусство дипломатии и красноречия, чтобы убедить клиента.
- Другой случай: клиент опасается за персональную информацию своих посетителей. А вдруг вы по IP соберете базу клиентов и сольёте её на сторону? Это опять вопрос доверия. Кроме того, ваш клиент может удалить все IP из журнала, если только эти IP не относятся к поисковым ботам.
- Но хуже всего – если запись логов отключена, потому что владельца сайта журнал посещений не интересует, и ему жалко места на сервере. Да, архивы с логами могут занимать много места.
Какой объём данных необходим
Всё зависит от анализируемого сайта и поставленных задач. В некоторых случаях достаточно журнала за неделю, чтобы диагностировать важные ошибки. В других случаях понадобятся данные за квартал или даже за полгода.
В любом случае, даже данные за прошлый год могут быть вам полезны для понимания общей картины в исторической перспективе. А некоторые системные закономерности можно выявить только на очень больших выборках, за период от года и больше.
Имейте в виду: обработка логов – ресурсоемкий процесс. Если для анализа вы используете какие-то десктопные приложения, и загружаете огромные журналы, это может «положить» вашу машину. Например, только загрузка логов в 2 ГБ размером в программу-анализатор у меня как-то заняла 30 минут (на 4 ГБ оперативной памяти). Если есть возможность – используйте внешние сервисы и облачные решения, или машину помощнее.
Какие данные из логов понадобятся
- Запрошенный URL: здесь будет показан URL-адрес, просканированный пользовательским агентом.
- Временная метка: показывает, когда (точная дата и время) пользовательский агент запрашивает сканирование URL-адреса. В приведенном выше примере строка журнала — [22/Aug/2023:21:281:14 +0300].
- Удаленный хост: здесь будет показано, какой IP-адрес запрашивается для сканирования URL-адреса. Если вы ищете события файла журнала робота Googlebot, вам нужно будет найти только IP-адреса, начинающиеся с 66.249. В приведенном выше примере это 66.249.76.201.
- Пользовательский агент (User0Agent): здесь будет показано, какой тип пользовательского агента запрашивается для сканирования URL-адреса. Если мы возьмем IP-адреса, начинающиеся с 66.249, в этом случае это могут быть «Googlebot», «Googlebot Smartphone», «Googlebot Image» и другие, связанные с пользовательскими агентами Googlebot. В приведенном выше примере это «Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/92.0.4515.119 Mobile Safari/537.36 (совместимый; Googlebot/2.1; +http) ://www.google.com/bot.html)».
- Метод: показывает, был ли URL-адрес запрошен у определенного ресурса как метод запроса «GET» или URL-адрес был обработан для определенного ресурса как метод «POST». Во многих случаях запросом метода будет GET, который является наиболее распространенным методом запроса HTML. В приведенном выше примере указано как «GET».
- Версия HTTP: здесь будет показана версия HTTP. Я видел версию HTTP во многих случаях как 1.1 или 2.0. В приведенном выше примере — HTTP/1.1.
- Код ответа: здесь будет показан возвращаемый код состояния URL-адреса, например «200-ОК», «301 постоянное перенаправление», «404 не найден», «500 ошибка сервера» и т. д.
- Реферер: показывает, на какую страницу сканируется любой из связанных URL-адресов. Это может быть внешний или внутренний источник.
Чем анализировать логи
В принципе, можно открыть лог даже в обычном текстовом редакторе типа Notepad++, или переименовать в csv и открыть в Excel. Только будет это долго, не наглядно и трудно, поэтому лучше использовать специализированный софт или сервисы.
Наиболее эффективным способом работы с лог-файлами я считаю использование средств языка программирования Python. С его помощью вы в кратчайшие сроки можете извлечь любую заданную информацию, выгрузить её в заданном формате и импортировать в любую удобную среду для дальнейшего анализа или представления – от Miscosoft Excel до инструментов BI (будь то Power BI или Google Data Studio). Плюс такого подхода – невероятная гибкость и полнота возможностей. Минус – вы должны знать Python хотя бы на уровне новичка.
Если вы не владеете Python – не беда: можно использовать готовые решения для чтения лог-файлов. Вот лишь некоторые из них.
- Screaming Frog Log File Analyzer – условно-бесплатная десктопная программа, мой выбор. Главный минус – это необходимость загружать логи вручную. Зато есть всё, что нужно для комфортной работы. Вы можете выбрать, какие боты вас интересуют, и даже проверить, не фейковые ли они.
- GamutLogViewer – достаточно старая уже десктопная утилита для работы с логами множества форматов. А значит, умеет фильтровать, сортировать, искать, но не задумана изначально для нужд оптимизатора.
- JetOctopus – веб-сервис. Платный. Есть бесплатный тестовый период на неделю.
- Oncrawl – веб-сервис, есть двухнедельный бесплатный период.
- SEOLYZER – веб-сервис, есть бесплатный тариф с ограничением в 10 тысяч URL.
- ELK Stack – бесплатный пакет из трёх платформ с открытым кодом. Если хотите поработать ручками, ELK может стать отличным инструментом для решения многих задач, в том числе и для обработки логов большого объёма.
Разумеется, это далеко не полный набор инструментов. Если вы никогда раньше не работали с логами, начните со Screaming Frog. Дополнительно можно посмотреть инструментарий для анализа логов тут, но для нужд поисковой оптимизации это уже лишнее.
Почему анализ логов важен для SEO
У вас может быть прекрасный (с вашей точки зрения) сайт: красивый, быстрый, удобный, с уникальным контентом, большим ссылочным профилем. И при этом плохо ранжируемый, медленно индексируемый. Причины могут крыться во взаимодействии сайта с другими объектами в интернете. Понять это можно только с помощью анализа логов.
Например, может оказаться, что на сайте есть изолированные от роботов разделы, появившиеся в результате технических ошибок или взлома. Или весь краулинговый бюджет расходуется на системные папки, которые сканировать вообще не надо. Или роботы заходят по внешним ссылкам на давно несуществующие разделы и страницы. Или по каким-то причинам поисковые роботы считают наиболее важными вовсе не те страницы, которые считаете важными вы.
Не менее важно понимать проблемы сканирования сайта в динамике. В этом случае нужно оценивать, получают ли поисковые роботы полную версию страниц, или сервер отдаёт им периодически файл-пустышку (софт 404) – для распознавания этого факта надо смотреть, не отличаются ли размеры страницы за период. Все ли необходимые ресурсы получают поисковики при обращении к странице? Это может сказываться на возможности полноценно рендерить (отрисовывать) страницу. Поисковые роботы должны получать ровно то же, что получают посетители-люди. Без анализа логов такую информацию нельзя получить никакими другими средствами.
Пример из практики
Сайт компании, занимающейся ремонтом квартир, офисов и частных домов. Отличные позиции в Яндекс – и отсутствие трафика из Google. Аудит показал, что по непонятным причинам множество страниц сайта роботам Google известны, но не сканируются, и потому не в индексе. Search Console никакой внятной информации на этот счёт не предоставляет. Возраст сайта – 4 года, ссылочный профиль в порядке.
После анализа логов, собранных за месяц, была обнаружена своеобразная ловушка для ботов, куда гуглобот заходил и уже не возвращался: до крайности кривой плагин WordPress, предназначенный, формально, для улучшения быстродействия, работал как чёрная дыра для роботов.
После внесения корректировок и добавления запрещающих директив гуглобот потерял интерес к плагинам и начал методично вносить в индекс целевые странички. Надеюсь, рост продолжится и дальше.

Варианты использования логов для SEO
Вот основные задачи, решаемые с помощью анализа логов.
- Управление краулинговым бюджетом (лимитами сканирования сайта)
- Исправление серверных ошибок
- Расстановка приоритетов для сканирования сайта поисковыми роботами
- Устранение из списка сканирования ненужных страниц
- Выявление больших или медленных страниц
Разберем эти вопросы более подробно.
Анализ краулингового бюджета
Краулинговый бюджет – это количество страниц, которые бот может просканировать за заданный период времени. В случае с Яндекс об этом можно не беспокоиться, но если речь идёт о ботах Google – это может быть проблемой.
Важно, чтобы лимит сканирования тратился на правильные страницы, а не на скрипты, страницы под редиректами, битые ссылки, дубли и т.п.
Проанализировав логи, вы можете понять, какие URL надо закрыть от сканирования с помощью robots.txt или метатегов и каких поисковых систем это касается. Ниже – пример: бот Яндекс самое пристальное внимание уделяет тегам на моём сайте, которые я использую в основном для вывода контента в некоторых блоках, а сами страницы тегов никакой уникальной информации не содержат. Следовательно, мне стоит прикрыть эти страницы от Яндекса.

Яндекс уделяет чрезмерное внимание тегам моего сайта. Следовательно, странички надо оптимизировать или закрыть от индексирования, чтобы не расходовать лимиты обхода впустую.
Правка ошибок серверных кодов состояния
С помощью программ для технического аудита сайта (типа Screaming Frog SEO Spider) вы можете получить список ошибок кодов состояния и получить список перенаправлений. Однако с помощью локального поискового робота вы не узнаете, с какими ошибками сталкивается реальный поисковый бот.
Серверные ошибки могут влиять как на производительность вашего сайта, так и на его ранжирование. Например, получив ошибки типа 500 (сервер не может обработать запрос по непонятной причине), поисковая система может выбросить страницы из индекса, а сайт понизить в выдаче на уровне хоста как некачественный.
В этом случае нужно попробовать настроить сервер так, чтобы вместо 500-х он отдавал 503, что означает временную недоступность сервера. Тоже ничего хорошего, но всё же лучше, чем деиндексация важных страниц.
Если вы видите большое количество 404-х – надо понять, с чем они связаны. Обычно речь идёт о битых ссылках либо на самом сайте, либо на внешних ресурсах. И если битые ссылки на своем сайте нужно просто исправить или удалить, то для внешних ссылок проще настроить постоянные (301) редиректы на существующие актуальные URL.
Рядовая ситуация. Владелец решил обновить свой сайт, структура URL не была сохранена, а редиректы никто не настраивал. В результате все старые ссылки на сайт ведут на несуществующие страницы. Конечно, найти такие ссылки можно и с помощью внешних сервисов, если они успели попасть в базы. Анализ логов намного точнее покажет вам, откуда по старым ссылкам приходят роботы или люди, и вы решите, куда их стоит перенаправлять, чтобы сохранить ссылочный вес.
Расстановка приоритетов сканирования
Может оказаться так, что значительная часть вашего сайта не сканируется вообще. А значит, вы теряете трафик, а с ним и конверсии. Этих страниц просто нет в индексе.
Причины могут быть самыми разными: отсутствие входящих ссылок, технические проблемы.
Другая распространенная проблема: второстепенным URL боты уделяют намного больше внимания, чем основным страницам. Например, на сайте интернет-магазина роботы могут заходить в блог, но игнорировать коммерческие страницы.
С помощью анализа логов за достаточно продолжительный период вы можете выяснить, каким разделам роботы отдают приоритет, и попытаться сменить акценты. Задача это непростая, для её решения вы можете использовать как масштабирование и корректировки ссылочной массы, так и настройки приоритетов сканирования в XML-карте сайта. А может быть, стоит внести правки в контент страницы? – Вам решать в каждом конкретном случае.
Выявление больших или медленных страниц
Никто не будет спорить, что быстродействие сайта влияет на ранжирование и конверсию. Если пользователь не может дождаться загрузки страницы – он уйдёт, а если и останется, то едва ли решится что-то покупать. Если сайт ощутимо «тормозит», как-то страшно проводить денежные транзакции. В логах вы можете выявить самые большие по объему и самые медленные страницы.
Не надо думать, что большая страница – обязательно медленная. Однако в любом случае стоит оптимизировать изображения, избавиться от ненужных веб-шрифтов, отключить автовоспроизведение видео, включить GZIP-сжатие для текстовых ресурсов.
Оценка реальной доступности страниц для роботов
Если люди без проблем получают доступ к важным страницам сайта, это не значит, что так же беспроблемно доступ получают поисковые роботы. Робот ведет себя иначе, чем человек, и веб-сервер может заблокировать робота, определив его по ряду признаков. И ситуации могут быть очень неожиданные.
Пример из практики. Маленький (менее 500 страниц) сайт с b2b-предложениями товарного характера. При высокой текстовой релевантности и достаточном ассортименте – плохо ранжируется, плохо идёт в индекс, всё правки обнаруживаются через 3-4 недели.
Парсим. Обращаем внимание на стандартный момент: некоторый процент страниц никак не отвечает, и не попадает в анализ. Повторный парсинг (сразу же) – резкое увеличение процента таких не отвечающих страниц и уменьшение объёма сайта. И в браузере сайт уже не открывается, но доступен через прокси или VPN.
Первые две гипотезы: либо защита от роботов на уровне файерволла, либо нехватка системных ресурсов. Но вероятнее всего – именно защита. Спрашиваем хостера, в чем может быть проблема. Хостер привлекает системщиков и выясняется, что ip влетает в бан. Почему? – UA обращается к техническим доменам, перенаправляющим на парковочную страницу. В коде этих ссылок нет, просто так их не увидишь. Смотрим логи: поисковики тоже получают множество софт-404, если находят эти ссылки с каких-то страниц.
Оказалось, что в шаблон сайта были вшиты ссылки на чисто технические домены, перенаправляющих на парковочную страницу. Разработчики сайта оставили в произвольных местах шаблона эти ссылки, забыв поменять домен на рабочий. Как результат – блок любого бота при достижении какой-то глубины обхода и обращении к странице парковки. Ошибка локализована, остаётся перебрать файлы шаблона и заменить технические ссылки.
Блокировка спам-ботов и парсеров
Даже чрезмерно активный поисковый робот может создать серьезную нагрузку на ваш сайт. А теперь представьте, что вашему сайту создают проблему зловредные боты, парсящие ваш контент или ищущие дырки в безопасности.
Анализ логов поможет выявить подозрительную активность, частоту визитов фейковых поисковых ботов, изучить их поведение. А потом заблокировать их, если нужно.
Но имейте в виду: в robots.txt директивы писать не надо, потому что они их проигнорируют. Используйте htaccess.
На что обращать особое внимание во время анализа логов
Всё определяют цели и задачи вашего проекта, но есть несколько общих мест, которые должны стать частью регулярного аудита.
- Периодичность заходов роботов целевых поисковых систем. Если ваша приоритетная поисковая система – Google, и вот он ходил-ходил, да пропал – повод бить тревогу. Возможно, вы влетели под фильтр. А если и не ходил – надо думать, почему.
- Соответствие продвигаемых страниц наиболее часто сканируемым. Большинство программ и сервисов позволяет сопоставить список целевых страниц сканируемым и выяснить, есть ли проблемы. Для этого достаточно просто загрузить табличку с URL.
- Оценка характера 404-х. Это страницы, которые вы удалили, или кто-то поставил на вас “кривую” ссылку? Или это ссылка ведёт ещё на старую версию сайта, и по ней пытаются переходить посетители? – Тогда надо настраивать редирект на соответствующий контент.
- Выявление ресурсоёмких URL. Поисковые системы не хотят тратить системные ресурсы впустую. Если ваш сайт не имеет реальной ценности с точки зрения поисковика, но при этом его сканирование затратно для системы – так или иначе он будет пессимизирован. Выявить ресурсоёмкие страницы и скрипты можно с помощью анализа серверных журналов. Например, в актуальную версию Screaming Frog Lof File Analyzer встроена оценка “углеродного следа”, напрямую связанного с расходом вычислительных ресурсов.
Заключение
Анализ лог-файлов – важная часть технического SEO, предоставляющая уникальную информацию о взаимодействии вашего сайта с поисковыми роботами. Несмотря на кажущуюся «шумность» этих данных, оптимизатор может получить как точные сведения, так и ресурсы для инсайтов, позволяющих составить общую картину с использованием других источников данных: панелей вебмастеров и аналитических систем.


Виктор, тема с логами полезная. Но вот с примером не понятно.
> своеобразная ловушка для ботов, куда гуглобот заходил и уже не возвращался: до крайности кривой плагин WordPress, предназначенный, формально, для улучшения быстродействия, работал как чёрная дыра для роботов.
Что все-таки произошло? Если простыми словами.
Классическая ловушка для роботов, выражавшаяся в том, что плагин плодил бесконечное количество версий css и js вида *.css?v=*
Гуглобот слишком увлеченно обходил всё это богатство, на важные страницы сайта его ресурсов уже не хватало. Насколько я помню, вопрос был решен заменой плагина кэширования.
Факт, что без анализа логов проблема не могла быть обнаружена никаким другим способом.
Благодарю за статью. Можете подсказать, как именно использовать python для обработки логов? Я начинающий, и не знаю с чего начать.
Тема достаточно глобальная, и пожалуй, требует отдельной статьи.