Монолитный индекс – это список ключевых слов (терминов), связанных с заданной страницей, и состоящий как из слов, содержащихся на самой странице (в документе), так и во внешних связанных источниках (текстах ссылок, около-ссылочном тексте и т.п.).
Благодаря монолитному индексу страница может иметь видимость в поиске по ключевым словам, которые в принципе не содержатся на самой странице, но используются в связанных внешних страницах. Другой вариант – эти ключевые слова когда-то были на этой странице, и данные об этом сохранены в индексе поисковой системы.
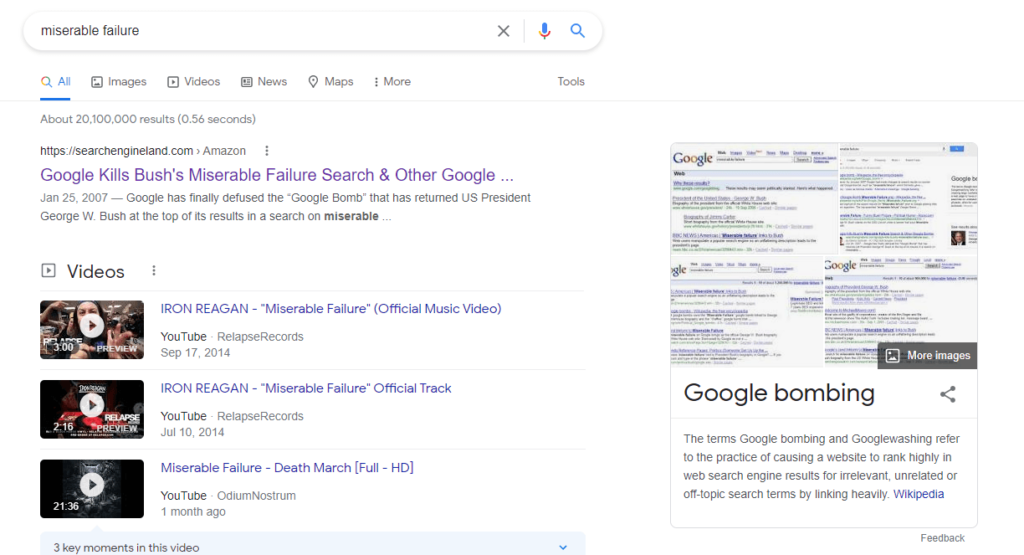
Широко известный пример проявления монолитного индекса – страница Дж.Буша-младшего на сайте Белого Дома. Страница ранжировалась в Google по запросу «жалкий неудачник» (“miserable failure”) благодаря тому, что ссылки с таким анкором были размещены на эту страницу. Это явление было названо “google bombing”.
В рамках SEO возможности монолитного индекса используются для подклеивания заданных ключевых слов, когда есть технические или другие ограничения. Группа ключей, входящих в кластер, может включать пару сотен элементов, и не все их можно включить в текстовый контент страницы. Чтобы получить максимально большое соответствие всем ключам кластера, используются внешние входящие ссылки, в тексты которых и добавляются заданные ключевые слова.
Важность использования монолитного индекса существенно сократилась со времен, когда наибольшее значение имели вхождения ключевых слов, алгоритмы, построенные на частотности терминов (tf*idf, BM-25 и аналогичные). С момента интеграции алгоритмов, построенных на принципах NLP (обработка естественного языка), поисковые системы могут оценивать релевантность страницы запросу и без прямых вхождений ключевых слов.
По каким метрикам оценивается монолитный индекс
В списке метрик, входящих в группу “Монолитный индекс” из просочившихся внутренних документов Яндекса, можно сделать ряд выводов и способах оценки этих метрик:
- Простой BM25 по тексту и линкам одновременно
- Все слова запроса есть в тексте + линках
- Есть точная форма всех слов запроса в тексте/линках
- Есть лемма всех слов запроса в тексте/линках
- BM25 с разными параметрами для разных полей, включая входящий анкортекст. Веса текста входящих на страницу ссылок нормируются в зависимости от delta page rank ссылки
и т.п. Как видно, всё строилось на простейших текстовых алгоритмах, оценивающих отдельно текст, отдельно ссылочные анкоры, отдельно леммы.
Не следует путать монолитный индекс с запросным индексом. Запросный индекс связан с видимостью заданного сайта в поиске по каким-то ключевым словам. Монолитный же индекс – просто список связанных с документом терминов, определяющих его семантику.
