XPATH (XML Path Language) – это язык запросов для работы с XML-документами. В SEO XPATH широко используется для парсинга веб-страниц и извлечения данных. Он позволяет точно указывать нужные элементы и их значения на странице для анализа и оптимизации сайта. Вот несколько примеров использования XPATH в SEO:
Содержание
скрыть
Извлечение заголовков страниц
//h1
Это выражение найдет все элементы `<h1>` на странице.
Извлечение текста из мета-тега “description”
//meta[@name=’description’]/@content
Это выражение найдет мета-тег с атрибутом `name` равным “description” и извлечет значение его атрибута `content`.
Извлечение URL-адресов всех ссылок на странице
//a/@href
Это выражение найдет все элементы `<a>` на странице и извлечет значение их атрибута `href`, который содержит URL-адрес ссылки.
Извлечение текста из элемента с определенным классом
//*[contains(@class,’class-name’)]/text()
Это выражение найдет все элементы, содержащие атрибут `class`, содержащий подстроку “class-name”, и извлечет текст внутри этих элементов.
Извлечение текста из списка элементов
//ul/li/text()
Это выражение найдет все элементы `<li>` внутри элемента `<ul>` (ненумерованный список) и извлечет текст каждого элемента.
Поиск элементов с определенным атрибутом
//*[@data-attribute=’value’]
Это выражение найдет все элементы, содержащие атрибут `data-attribute` со значением “value”.
XPATH предоставляет различные функции и операторы, которые могут быть использованы для более сложных запросов. Кроме того, его можно комбинировать с CSS-селекторами для определения конкретных элементов на странице. Обучение XPATH полезно для SEO-специалистов, поскольку позволяет более точно выбирать данные для анализа и оптимизации сайта.
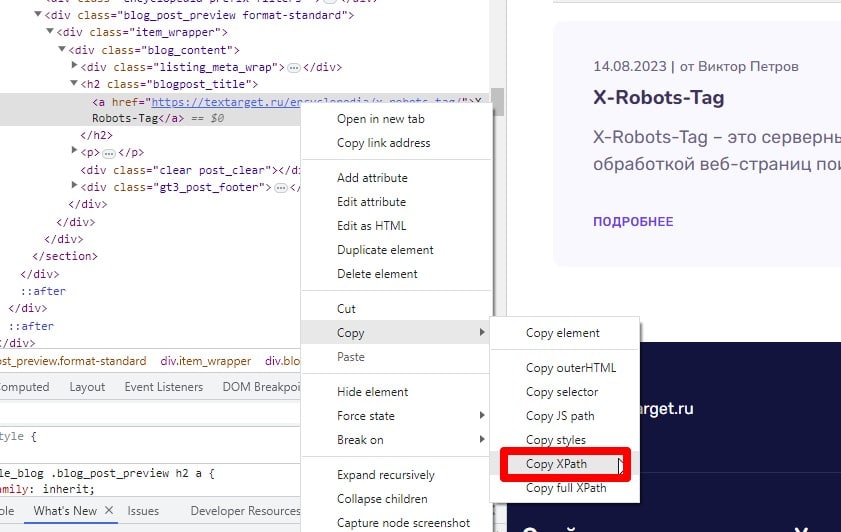
Для выявления заданного элемента можно использовать консоль браузера или браузерные расширения. После обнаружения XPATH заданного элемента данные можно извлечь с помощью парсера (например, Screaming Frog SEO Spider).